
It’s no surprise, that in 2026, large language models (or LLMs to be short) are more capable than ever. They can reason, write, and even code, but they still have one big limitation: they can’t access the live web by default.
That’s where the Firecrawl MCP Server comes in. It gives your LLM-powered apps the ability to:
- Browse and scrape live websites
- Extract structured data
- Run automated research
- Stay up-to-date with real-world information
And it does all this through a simple, standardized interface called MCP (Model Context Protocol), so you don’t need to build complex scrapers or custom tools.
In this article, you’ll learn exactly why Firecrawl MCP Server is one of the must-have tools for LLM workflows in 2026.
We’ll cover:
- What it is and how it works
- How to install and configure it
- The key Firecrawl MCP Server features you’ll love
- Real-world examples of what you can build
- How to troubleshoot common issues
By the end, you’ll know how to get started and how to give your LLM apps the live web access they’ve been missing.
Let’s dive in. First, let’s start with the basics: what exactly is Firecrawl MCP Server, and why should you care?
What is Firecrawl MCP server?
Turn on your imagination: you’re building an LLM-powered app for startup lead generation and you want it to pull in the latest news, product reviews, or stock updates, right from the web.
But LLMs (like Claude or GPT) can’t browse the web on their own. They rely on what they were trained on, which quickly gets outdated.
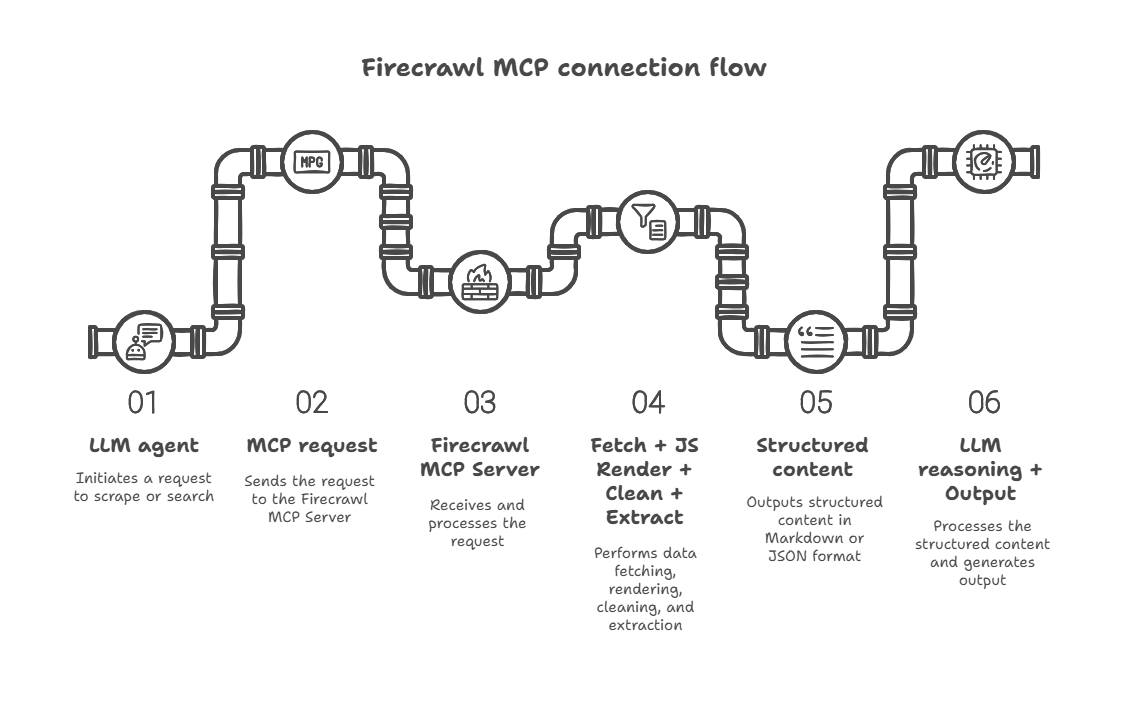
You need Firecrawl’s MCP server because it acts like a smart middleman between your LLM agent and the live internet. And. what’s MCP?
MCP is an open standard from Anthropic. It lets LLMs request live data from specialized “MCP servers” (you know, like Firecrawl), which know how to browse, extract, and clean web content in a way that’s safe and useful for the model.
Here’s how you’d typically use it (in short):
- You deploy a Firecrawl MCP server (you can run it in the cloud or on your own server).
- You register it as an MCP endpoint in your tool of choice: apps like Cursor, or even directly in Claude.
- Your LLM makes a request (called a “scrape” or “search”) for a page it needs.
- Firecrawl grabs the page, renders it (including JavaScript-heavy sites), cleans it up, and sends it back, ready for the LLM to use.
You don’t need to teach the LLM how to crawl websites. Firecrawl handles all that behind the scenes.
Why is it better than old-school scraping? Easy!
Classic scrapers struggle with modern websites. Think of sites built with React or those that load content through JavaScript. Firecrawl handles those with ease. It’s built on its powerful web-crawling engine, and adds Firecrawl MCP Server features that make your life easier:
- JavaScript rendering → works perfectly on dynamic sites.
- Batch URL crawling → fetch lots of pages at once.
- Smart URL discovery → automatically finds related content.
- Retries and rate limiting → handles errors and avoids blocks.
- Content filtering → strips out ads, sidebars, and clutter.
The result? Clean, structured data (Markdown, JSON, HTML, screenshots), ready for your LLM to use in its reasoning.
And the best part, with Firecrawl MCP, your LLM gets live knowledge, without waiting for the next training run. You can:
- Ground responses in real-time data = reduce hallucinations.
- Automate research = scrape and analyze multiple sources on demand.
- Scale up = batch scrapes to feed lots of fresh context quickly.
For example:
- Build an AI that summarizes today’s top news.
- Have a chatbot that gives current product prices.
- Let your agent do fact-checking on the fly.
Now that you know what it is, let’s walk through how to install it. It’s quick and easy to get started. But first, let’s…
Use MCP to turn signals into sales
With MCP, your AI finds trigger events and intent-rich leads, so you can be first to reach out and close the deal.
How do you install the Firecrawl MCP server?
Good news: setting up Firecrawl MCP Server is quick and flexible (relatively!). You’ve got a few ways to do it, depending on how you want to use it.
Here’s a quick comparison to help you choose the best install option:
| Install option | How to run it | Best for |
npx (quick test) | One-off CLI command | Testing, short sessions |
| Global install | npm install -g + CLI command | Frequent use, scripting, CI/CD |
| Self-hosted | Clone repo + run with config | Full control, enterprise, on-prem setup |
I’ll walk you through each option, pick the one that fits your workflow best.
1. Quick test run (npx)
If you just want to try Firecrawl right away (no installs, no setup!), use npx. It downloads and runs the server on demand.
Perfect for testing or short sessions.
Here’s the command: env FIRECRAWL_API_KEY=fc-YOUR_API_KEY npx -y firecrawl-mcp
That’s it. No global install, nothing to clean up after.
2. Install globally (npm)
If you’re using Firecrawl regularly (in scripts or CI), it makes sense to install it globally with npm.
You’ll then have firecrawl-mcp available system-wide:
npm install -g firecrawl-mcp
firecrawl-mcp # runs the server
This is great if you want to automate things or run the server often.
3. Self-hosted setup
Prefer to host it yourself? No problem, you can clone the repo and deploy it however you like (cloud, on-prem, offline).
Here’s how:
git clone https://github.com/pashpashpash/mcp-server-firecrawl.git
cd mcp-server-firecrawl
npm install
npm run build
To run it:
env FIRECRAWL_API_URL=https://your-domain.com \
FIRECRAWL_API_KEY=YOUR_KEY \
firecrawl-mcp
Just point FIRECRAWL_API_URL to your self-hosted endpoint. You’re in full control of your b2b api integration.
Integration with popular tools
Firecrawl MCP also plugs right into tools you probably already use. Here’s how to set it up:
Cursor (v0.45.6+)
If you’re using Cursor, you can add Firecrawl MCP right from the app settings.
First, go to: Cursor Settings → Features → MCP Servers. Then add this:
{
"mcpServers": {
"firecrawl-mcp": {
"command": "npx",
"args": ["-y", "firecrawl-mcp"],
"env": {
"FIRECRAWL_API_KEY": "YOUR_API_KEY"
}
}
}
}
On Windows, use this instead:
"command": "cmd",
"args": ["/c", "set FIRECRAWL_API_KEY=…", "&&", "npx", "-y", "firecrawl-mcp"]
Claude Desktop
To integrate Firecrawl with Claude Desktop, just add this to your claude_desktop_config.json:
"mcpServers": {
"mcp-server-firecrawl": {
"command": "npx",
"args": ["-y", "firecrawl-mcp"],
"env": { "FIRECRAWL_API_KEY": "YOUR_API_KEY" }
}
}
Or, if you want an even simpler setup, use the hosted SSE endpoint:
"url": "https://mcp.firecrawl.dev/YOUR_API_KEY/sse"
Windsurf
If you’re working in Windsurf, add this to your ./codeium/windsurf/model_config.json:
{
"mcpServers": {
"mcp-server-firecrawl": {
"command": "npx",
"args": ["-y", "firecrawl-mcp"],
"env": { "FIRECRAWL_API_KEY": "YOUR_API_KEY" }
}
}
}
VS Code extension
You can also use Firecrawl directly inside VS Code. Just update your settings.json like this:
"mcp": {
"inputs": [{
"type": "promptString",
"id": "apiKey",
"description": "Firecrawl API Key",
"password": true
}],
"servers": {
"firecrawl": {
"command": "npx",
"args": ["-y", "firecrawl-mcp"],
"env": { "FIRECRAWL_API_KEY": "${input:apiKey}" }
}
}
}
Or, you can also share this with your team by adding it to your project in .vscode/mcp.json.
Environment variables & config tips
A couple key env vars you’ll want to know:
FIRECRAWL_API_KEY— Required if using Firecrawl’s cloud service.FIRECRAWL_API_URL— Set this if you’re running a self-hosted instance.
Want to fine-tune retries?
FIRECRAWL_RETRY_MAX_ATTEMPTS (default: 3)
FIRECRAWL_RETRY_INITIAL_DELAY (default: 1000 ms)
FIRECRAWL_RETRY_MAX_DELAY (default: 10000 ms)
FIRECRAWL_RETRY_BACKOFF_FACTOR (default: 2)
You can also set credit usage alerts:
FIRECRAWL_CREDIT_WARNING_THRESHOLD
FIRECRAWL_CREDIT_CRITICAL_THRESHOLD
With these install options and integrations, getting Firecrawl MCP Server up and running is smoother than ever, whether you just want to test it out, install it for daily use, or fully integrate it into your favorite tools.
Once it’s running, you’ll want to know what tools you can use. Let’s look at the core actions that make Firecrawl so powerful.
What core tools are available?
Now that you’ve got Firecrawl MCP Server installed, you’re probably wondering: What can it actually do?
Well, quite a lot.
Firecrawl MCP brings a powerful set of tools that let your LLM fetch, explore, and structure live web data through simple, standard actions.
You don’t need to reinvent crawling or scraping, just call these built-in tools through the MCP interface.
Let’s go through them:
scrape
This is your go-to tool for grabbing a single page. You point it to a URL, and Firecrawl returns:
- Clean Markdown
- HTML
- JSON
- Screenshots
It even handles JavaScript-heavy sites, uses proxies if needed, respects rate limits, and caches intelligently.
Great for when you want a neat version of one page, ready for your LLM to process.
batch_scrape
Got a list of URLs?
Instead of scraping one at a time, use batch_scrape to process them in parallel = fast and efficient.
Firecrawl handles retries, throttling, and errors automatically. Perfect for pulling a set of product pages, articles, or docs in one shot.
map
Want to discover new URLs on a site?
map will explore the links within a domain and return a list of pages, without fully scraping them.
Use this to:
- Build simple sitemaps
- Seed a bigger crawl later
- See what content is out there
crawl
Need to go deeper? Use crawl to traverse an entire site or subdomain = automatically following links.
It respects depth limits and filters, and returns structured content (Markdown or JSON) from each page it visits.
If you’re building an LLM with broad knowledge of a site, this is the tool to use.
search
Here’s one of the coolest features: search + scrape in one step.
You give Firecrawl a search query, then it runs the search and scrapes the top results for you.
One call = results + content.
This makes it super easy to collect info on a topic, even if you don’t know which URLs you want up front.
extract
Need structured data instead of full-page content? extract lets you define JSON schemas, and Firecrawl will pull exactly the fields you want = clean and ready to use.
Think of it like: “I want this site’s table of prices, in JSON.”
No more messy parsing. And, one more feature you probably might need for your sales…
MCP helps you reach the right lead, right now
Generect MCP constantly updates lead data + signals, so your AI knows who’s ready, and you never miss a moment.
deep_research
This is the high-level tool for complex topics.
You give it a subject, and Firecrawl will:
- Run searches
- Crawl key sources
- Scrape and synthesize results
In the end, you get a rich, multi-source answer = perfect for agents that need to “research” on their own.
generate_llmstxt
Want to prep a site for LLM use? generate_llmstxt automatically creates machine-friendly .txt files (like llms.txt and llms-full.txt).
It’s great for building training or fine-tuning data, especially when you want a clear, stripped-down version of a site’s text.
Here’s a handy cheat sheet:
| Tool | Use case | Returns |
| scrape | Single URL | Markdown / HTML / JSON / Screenshot |
| batch_scrape | Many known URLs | Array of page data |
| map | URL discovery | List of URLs |
| crawl | Full-site crawl | Multi-page structured output |
| search | Query + scrape results | Pages with content |
| extract | Structured data (schema) | Clean JSON |
| deep_research | Multi-source research | Synthesized summaries + sources |
| generate_llmstxt | Site-to-LLM text files | llms.txt / llms-full.txt |
As you can see, Firecrawl MCP Server isn’t just a scraper. It’s a full toolbox for giving your LLMs real-world knowledge.
Modern sites rely on JavaScript. Here’s how Firecrawl makes sure you capture all that dynamic content.
How does JavaScript rendering work?
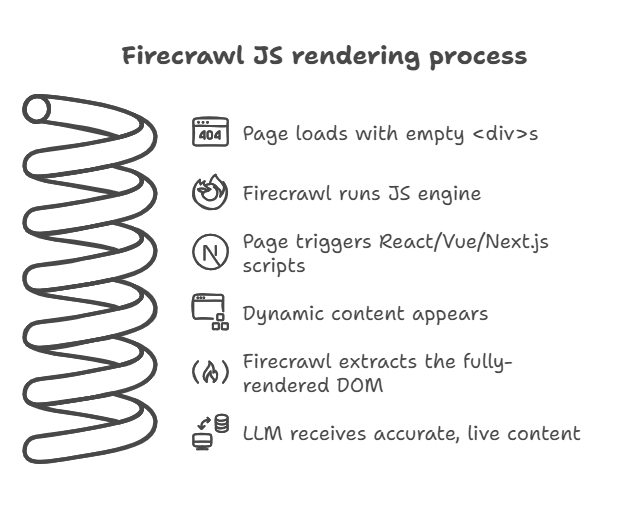
If you’ve tried scraping modern websites, you’ve probably run into this problem: the HTML looks empty.
No content, no articles…just blank <div> tags.
That’s because today’s sites (like Medium, Reddit, GitHub, and many docs platforms) don’t serve full pages anymore. They load a minimal shell, then use JavaScript to pull in the actual content.
Without JS rendering, you’ll miss it all.
That’s why Firecrawl MCP Server includes a full JavaScript rendering engine, so your LLMs can see the page exactly as a real user would.
Here’s how it works: when you run a scrape or crawl, Firecrawl doesn’t just grab raw HTML. Instead, it behaves like a browser:
- Runs the page’s JavaScript → it executes scripts, so React, Vue, Next.js, and other frameworks load fully.
- Waits for the page to “settle” → it waits until the network is quiet and the DOM is stable. That way, you don’t miss lazy-loaded content, like comments, infinite scroll, or images.
- Extracts the final version of the page → you get a fully rendered, accurate version of the content, ready for your LLM to process.
Why this matters? Without JS rendering, you’ll get partial (or blank) pages. Here are a few real-world examples with what Firecrawl’s JS engine makes sure you’ll capture:
| Site example | Without JS rendering | With Firecrawl JS rendering |
| Medium.com | Blank page, empty <div>s | Full article content |
| Reddit.com | No posts, no comments | Full post threads |
| GitHub | No issues, no contributor data | Complete project pages, issues, stats |
| docs.firecrawl.dev | Missing nav & content | Full interactive documentation |
Exactly as a real user sees it. To put it visually, here’s what happens when Firecrawl handles a modern, JS-heavy site:
As Rohan Paul puts it: “The JavaScript rendering engine of Firecrawl MCP Server… seamlessly executes those scripts, allowing content to load as it does in a real browser.”
Of course, performance matters too. Let’s see how Firecrawl handles efficiency, retries, and cost control.
How is efficiency handled?
When you’re running LLM-powered apps in 2026, speed and cost really matter. You don’t want delays, wasted credits, or errors clogging up your pipelines.
That’s why Firecrawl MCP Server is built with efficiency and reliability baked in. It manages load, handles retries, and keeps an eye on your usage, so you can focus on building, not debugging.
Here’s how it works:
Smart batch processing
If you’re using tools like batch_scrape, crawl, or extract, Firecrawl automatically:
- Respects rate limits (for example, 500 requests per minute on the Standard plan)
- Processes requests in parallel to maximize speed
- Queues and throttles smartly, so you don’t hit your caps or trigger blocks
You don’t need to micromanage it. Firecrawl balances the load for you, keeping things fast and compliant.
Automatic retries
Sometimes requests fail due to rate limits, network hiccups, or temporary site issues.
Firecrawl handles that automatically. If a request fails:
- It will retry up to 3 times by default
- The delay between retries starts at 1 second and doubles each time (up to 10 seconds)
You can tune these settings anytime with environment variables:
FIRECRAWL_RETRY_MAX_ATTEMPTS
FIRECRAWL_RETRY_INITIAL_DELAY
FIRECRAWL_RETRY_MAX_DELAY
FIRECRAWL_RETRY_BACKOFF_FACTOR
This protects your workflows from random errors, without you having to watch over every request.
Credit monitoring
If you’re running in the cloud, Firecrawl also keeps an eye on your credit usage. It tracks consumption and will log:
- Warnings when you get close to your monthly quota
- Critical alerts if you’re at risk of hitting your limit
That way, you won’t get caught off guard by surprise billing or stopped services = super useful for big crawls or long-running jobs.
Firecrawl also logs key performance data, like:
- Requests and responses
- Retry counts
- Credit checks
- Rate-limit events
You can plug this into your own observability tools (Grafana, dashboards, etc.) to get a live view of what’s happening.
In short, here’s what makes Firecrawl both fast and reliable:
- Batch + throttling → parallel, efficient fetching
- Retries → resilient to transient errors
- Backoff controls → avoids hot loops
- Credit monitoring → protects against runaway usage
Together, these features let you scale LLM + web access smoothly, without worrying about costs or reliability.
Next, you’ll learn how Firecrawl helps your LLM not just fetch pages, but discover new content and structure the data.
What tools help discovery and structure?
Once your LLM can browse the web, the next step is helping it discover useful content and turn it into structured insights, fast.
That’s where Firecrawl MCP Server really shines. It’s not just a scraper. It gives your agent tools to explore, extract, and synthesize information intelligently.
Here’s how the key tools work:
Map + Crawl = find hidden content
A lot of valuable pages on the web aren’t linked from the homepage or a sitemap. You need to dig a little deeper.
That’s where map and crawl come in:
- Use
mapto scan a domain and uncover its internal structure. It finds links and surfaces “orphan” pages that might otherwise stay hidden. - Then follow up with
crawlto pull content from those pages, controlling how deep you go (you can set limits on depth or URL count).
Together, this combo lets your LLM:
- Explore site hierarchies
- Find pages humans wouldn’t easily discover
- Build a full view of any website
Extract = turn content into clean data
Sometimes you don’t want a full page. You want structured data.
That’s what extract is for. It takes the raw content and applies JSON schemas or custom prompts, turning it into:
- Product info
- Articles
- Metadata
- Whatever your LLM pipeline needs
Instead of parsing messy HTML later, you get clean JSON, ready to use in your app or model.
Deep research = go beyond scraping
If you want your agent to synthesize knowledge from multiple sources (not just scrape pages), use deep_research.
Here’s what it does:
- Runs search queries
- Crawls key sources
- Scrapes useful content
- Uses an LLM to analyze and summarize the results, with sources and citations
It’s like automating an entire research project. Perfect for answering complex questions or building knowledge bases.
Let’s take one last quick glance:
| Workflow | Tools used | Outcome |
| Discover & fetch | map + crawl | Hidden site pages, with limits |
| Structure data | extract | Clean JSON, based on your schema |
| Perform research | deep_research | LLM-synthesized summaries + sources |
With these tools, Firecrawl becomes more than a scraper. It’s a full discovery engine for your LLMs.
Things don’t always go perfectly. Here’s how Firecrawl keeps you informed and handles errors gracefully.
How do logging and error handling work?
When you’re running LLM apps at scale, things don’t always go smoothly. You need to know what’s happening and make sure your workflows stay resilient.
Firecrawl MCP Server is built to give you exactly that: clear logs, smart error handling, and automatic recovery. Here’s a simple view of what Firecrawl logs and why it helps:
| What’s logged | Why it matters |
| Request start/completion | See what’s running |
| Performance metrics | Spot slow endpoints |
| Retry attempts | Debug flaky networks, rate limits |
| Credit usage | Manage costs, avoid surprises |
| Errors (structured JSON) | Helps agents recover, retry or adjust |
Let’s walk through how it works:
Transparent logging
Every operation your Firecrawl server runs, no matter if it’s a scrape, crawl, or batch, is logged in real time. You’ll see messages like:
[INFO] Starting scrape for URL: ...
[INFO] Batch operation queued...
These logs give you:
- Visibility into progress → know what’s running and when
- Performance metrics → track timing and throughput
- Credit usage → get alerts when you approach credit limits
- Rate-limit hits → see when you’re hitting caps, and what’s being retried
You can watch this in your console or feed the logs into monitoring tools (Grafana, CloudWatch, etc.).
Smart retries and network resilience
The web is unpredictable, and sometimes requests will fail.
Firecrawl handles that for you. If there’s a transient error (like a 429 rate limit or a flaky network), Firecrawl:
- Automatically retries failed requests
- Uses exponential backoff: starting at ~1 second, doubling each time (up to ~10 seconds)
You can tune these with environment variables if needed:
FIRECRAWL_RETRY_MAX_ATTEMPTS
FIRECRAWL_RETRY_INITIAL_DELAY
FIRECRAWL_RETRY_MAX_DELAY
FIRECRAWL_RETRY_BACKOFF_FACTOR
This protects your workflows from temporary blips, so one bad request doesn’t break your whole process.
Structured error responses
When an error does happen, Firecrawl returns a clear, structured JSON message.
Example:
{
"content": [
{
"type": "text",
"text": "Error: Rate limit exceeded. Retrying in 2 seconds..."
}
],
"isError": true
}
That way:
- You (or your LLM agent) can understand the error
- You know if it’s temporary or permanent
- You can log it, retry it, or take other action
No more digging through vague error codes = everything is explicit and machine-readable.
What this means for you
In short, Firecrawl gives you:
- Full observability → see exactly what’s happening at all times
- Robust resilience → auto-retries and backoff keep things running smoothly
- Clear error handling → structured errors that your agent can act on
By combining transparency with smart recovery, Firecrawl helps your LLM apps stay reliable, even when the web isn’t.
Want more control? Let’s look at the advanced settings you can tweak to fine-tune Firecrawl for your workflows.
How do you configure advanced settings?
Once you’ve got Firecrawl MCP Server running, you might want to fine-tune it. Maybe you want to adjust how retries work. Maybe you need to stay within a budget, or focus on just certain parts of a page.
The good news? Firecrawl gives you a ton of control, all through simple environment variables.
Let’s walk through what you can tweak and how to do it:
Fine-tune retries and backoff
When scraping the web, not every request will succeed on the first try. Sites can be slow, networks can drop.
Firecrawl handles retries for you, but you can control exactly how and when it retries.
Just set these variables:
export FIRECRAWL_RETRY_MAX_ATTEMPTS=5 # Max retries (default 3)
export FIRECRAWL_RETRY_INITIAL_DELAY=2000 # Start at 2 seconds (default 1 second)
export FIRECRAWL_RETRY_MAX_DELAY=30000 # Cap backoff at 30 seconds (default 10 seconds)
export FIRECRAWL_RETRY_BACKOFF_FACTOR=3 # Multiply delay by 3 each retry (default 2)
This creates an exponential backoff, so retries don’t hammer the server and things stay smooth.
Manage usage and credits
If you’re using Firecrawl’s cloud service, you’ll want to stay on top of credit usage.
To do that, set these:
export FIRECRAWL_CREDIT_WARNING_THRESHOLD=2000
export FIRECRAWL_CREDIT_CRITICAL_THRESHOLD=500
Now Firecrawl will log:
- Warnings when you’re nearing your limit
- Critical alerts when you’re close to running out
This helps you avoid surprises, especially for big projects or long-running jobs.
Also: under heavy load, Firecrawl automatically queues and throttles requests, so you won’t accidentally blow past rate caps.
Control what gets scraped
Sometimes, you just want the main content (don’t want the whole page without any particular reason). Or maybe you want to test how a site looks on mobile vs desktop.
Here’s how to do that:
Filter content by tag
Use includeTags and excludeTags to focus on specific parts of the page:
- Only scrape articles (and skip navbars, footers, ads, etc.)
- Narrow down the content you send to your LLM
Switch between mobile and desktop view
Emulate different devices:
mobile: true # Phone-like rendering
mobile: false # Standard desktop view
This lets you:
- Test how sites behave across devices
- Capture the mobile version of a site (which can sometimes be simpler and easier to scrape)
With these advanced settings, you’re fully in control:
- Tune retries and backoff
- Manage credits and throttle usage
- Filter content and adjust viewport
It’s all designed to help you optimize performance and costs. Now, let’s get practical! Here are some real-world ways people are using Firecrawl today.
What real‑world scenarios shine?
Firecrawl MCP Server is a serious enabler for building practical, high-impact workflows with live web data.
You’re not limited to scraping pages. You’re giving your LLM-powered apps the ability to monitor markets, track changes, and gather structured knowledge in ways that really matter in 2026. Here’s how Firecrawl fits into a real-world workflow:

Let’s look at a few standout use cases:
Competitor product research
Need to know what your competitors are up to?
With Firecrawl, you can scrape:
- Product listings
- Specs and features
- Prices, reviews, and availability
And thanks to structured extraction, you’ll pull this data directly into JSON, ready for your LLM agents to analyze.
Teams focused on b2b saas lead generation already use this in tools like Cursor and Claude agents for market research and competitor analysis, turning raw site content into actionable intelligence.
How to do it:
- Run
crawlorbatch_scrapeon competitor sites - Use
extractto pull key fields - Feed the results into your analytics or LLM workflows
Need something advanced for your prospecting? We’re building a solution…
Use MCP to feed your AI high-intent leads
No more static CRM data. MCP helps your AI find leads showing real intent, then preps outreach for you.
Price monitoring & change detection
Want to track price changes for your own products or the competition? Firecrawl makes it easy to automate that.
You can:
- Set up scheduled scrapes with
batch_scrapeorcrawl - Use
extractto grab the price fields - Detect changes: drops, hikes, trends
- Trigger alerts or UI updates
Many teams are already building real-time price trackers using Firecrawl, Python, and Streamlit following public tutorials from early 2026.
It’s a great way to stay competitive and let your LLM-powered app watch the market for you.
Documentation cloning & structured export
Need to build a knowledge base from web docs? Want offline access to an API’s documentation? Firecrawl makes that simple.
You can:
- Use
map+crawlto explore an entire docs site - Apply
extractto turn pages into structured JSON or Markdown - Feed that content into RAG pipelines
- Build offline docs or even clone full sites
Companies like Replit and OpenAI already use Firecrawl this way – to power better LLM training and improve app experiences with structured knowledge.
It works great for:
- Documentation cloning
- API data extraction
- Offline backups
- Structured datasets for LLMs
Ran into a problem? No worries! Here are simple fixes for common issues, especially on Windows.
How do you troubleshoot common issues?
For the most part, Firecrawl MCP Server works great out of the box. But if you’re running it through Cursor, Firecrawl MCP (especially on Windows) and you might run into a couple of common quirks.
Here’s a quick troubleshooting guide to help you fix them fast:
“Client Closed” error in Cursor
One of the most common issues: you add Firecrawl in Cursor’s MCP settings, but it shows a “Client Closed” error.
Here’s how to fix it:
Check your config
First, double-check your mcp.json. It should look like this:
{
"mcpServers": {
"mcp-server-firecrawl": {
"command": "npx",
"args": ["-y", "firecrawl-mcp"],
"env": { "FIRECRAWL_API_KEY": "YOUR_KEY" }
}
}
}
Many users have confirmed this config works on the Cursor forums.
Windows-specific workaround
If you’re on Windows, wrap the command like this:
"command": "cmd",
"args": ["/c", "npx", "-y", "firecrawl-mcp"],
"env": { "FIRECRAWL_API_KEY": "YOUR_KEY" }
Also: Only run one MCP server at a time in Cursor. Having multiple active servers often causes conflicts and “Client Closed” errors.
Check your PATH
Make sure:
- Node.js, npm, and npx are installed on Windows (not just WSL).
- They’re included in your system PATH.
Without this, Cursor won’t be able to run Firecrawl.
Windows path quirks & one-server limit
Another thing to watch for: sometimes Cursor opens a blank PowerShell window, or closes the MCP server instantly.
This usually means:
- Node or the command wasn’t found
- Or multiple MCP servers are active
Again: Run just one MCP server at a time in your Cursor settings. That solves this in most cases.
Tips from the community for stable setup
Cursor and GitHub users have shared some extra tips:
Restart Cursor (or your whole system)
This clears out stale PATH or cached issues that can mess with MCP servers.
Clear he npx cache
If things get weird, run: npx clear-npx-cache
It often fixes strange execution failures.
Bundle custom MCP servers
If you’re using a custom or multi-file MCP server (like in TypeScript), bundle it into a single JS file with esbuild.
This avoids Cursor’s standard I/O quirks.
Debug with Process Explorer
On Windows, you can use Process Explorer to watch for servers that exit too fast. That helps you catch misconfigured commands.
So, to wrap up: if you run into trouble, don’t worry, you’re not alone. Most Firecrawl + Cursor MCP quirks boil down to:
- Getting the JSON config right
- Handling Windows command wrapping
- Running just one MCP server at a time
- Managing PATH and Node installs
And if all else fails, a simple restart or clearing your npx cache often does the trick.
Finally, let’s wrap it all up: why Firecrawl MCP Server is a tool you’ll love using in 2026.
What’s the takeaway?
So, after everything we’ve covered, why should you care about the Firecrawl MCP Server in 2026?
Here’s the short version: it’s one of the best ways to supercharge your LLM workflows with live, structured web data.
Why Firecrawl stands out? First, it gives you a level of flexibility that’s hard to match. With a single open-source MCP server, you can do it all:
- Scrape single pages
- Crawl entire sites
- Extract structured data
- Run search + fetch workflows
- Even handle multi-source research
And you get all this through the simple, standard MCP interface: no hacks or complex setups needed.
Next, it’s designed to fit your workflow, no matter if you’re just getting started or scaling up. You can begin experimenting locally with just npx.
When you’re ready, Firecrawl makes it easy to grow. That means self-hosting, plugging it into enterprise pipelines, or integrating with your favorite tools like:
- Cursor
- VS Code
- Windsurf
- Claude
Firecrawl adapts to your needs, big or small.
Finally, it’s built for the realities of working with live web data. You can trust Firecrawl to handle:
- JavaScript-heavy sites
- Rate limits and batch jobs
- Automatic retries when things go wrong
- Alerts before you hit credit limits
It’s made to keep your workflows running smoothly, even when the web gets messy.
Ready to give it a spin? Here are the core tools you’ll want to try first:
scrape,search,crawl→ fetch pages, run search-and-fetch, or crawl full sitesextract→ turn messy web content into clean JSONdeep_research→ get on-demand, LLM-powered research with sources
Want to dive deeper and stay up to date?
Here are some great places to explore:
Firecrawl MCP server Github repo & changelog. Check out the official repo → mendableai/firecrawl-mcp-server. You can find the ways to:
- Browse the code
- Track issues
- See what’s new and what’s coming
Official docs. Head to → docs.firecrawl.dev/mcp. You’ll find:
- Quickstart guides
- Advanced configs
- API references
- Changelog & demo playground
Community resources. You’ll also find a great community sharing tips and real-world examples:
- Reddit → real-world projects and ideas
- Cursor Forum → integration guides and troubleshooting
- Medium tutorials → deep dives on workflows like price monitoring and doc scraping
So, if you want to give your LLM apps live access to real-world data (and you want something open, flexible, and battle-tested), MCP Firecrawl Server is absolutely worth exploring.
Now’s the perfect time to start experimenting with Generect MCP and see how it can power up your projects in 2026.

